
✔️ 정보 과잉시대에 대한 대책을 찾아봅니다.
✔️ 정독까지 1분 38초
✔️ 정보를 바탕으로 전개하는 주장글
#0 끝도 없이 늘어나는 데이터들. 지금도 앞으로도.
IDC (International Data Corporation) 는 매년 디지털 데이터양에 관한 보고서를 발표합니다.
2005년에 0.13 제타바이트
…2012년에 2.8 제타바이드
…2020년에는 90 제타바이트
2025년에 생산/유통 될 디지털 데이터양은 175 제타바이트로 예측됩니다.😵

제타바이트가 실감이 안 나는 사람을 위해 가벼운 예시를 하나 들어볼까요?
1제타바이트는 2^70바이트 입니다.
이러면 조금 더 체감될까요.
8제타바이트를 바이트로 환산하면, 전 세계의 모래알 수와 비슷합니다!
불과 10년 만에 700배에 가까운 데이터가 생겨났습니다.
2012년에 IDC는 2020년 디지털 정보량이 40제타바이트에 보달할거라 예측했습니다.
허나 2020년 데이터양은 90제타바이트 이상으로 예측을 두 배 이상 웃돌고 있습니다.
과학이 발전함에 따라, 우리는 개인이 받아드리기에는 너무 많은 사실들을 알아냈습니다.
정보가 홍수처럼 범람하는 시대, 정보의 바다라는 말이 지겹도록 들리는 이유겠지요.
#1 알맹이 없는 열매를 까보는 노력들.
2012년 0.5%에 데이터만이 분석되었습니다. 보호받는 데이터는 19%에서 그쳤고요.
앞서 말했듯이, 정보는 기하급수적으로 정보는 늘어납니다.
그에 반해 유의미한 데이터는 정보 팽창속도에 비하면 충분히 확보되지 않는다고 봐도 무방해 보이고요.
이는 무의미한 데이터가 생산되기 때문이라고도 볼 수 있습니다.
하나의 사실로도 많은 디지털 컨텐츠가 생산됩니다.
블로그로, 커뮤니티로, 유튜브 채널로, 뉴스로, 그리고 스타트업 같은 새로운 서비스로.
인터넷이라는 공간은 점점 더 넓어지고 빼곡히 채워집니다.
빽뺵히.
세상은 점점 넓어지는데
같은 사실로 쓸모없는 컨텐츠들이 생산되고
알아야할 사실은 늘어만 가니
우후죽순 넓어지는 정보 사이에서 길을 잃는게 일상입니다.

순전히 정보를 이해하기 쉽게 전달하려는 생각과
금전전 이익을 취하려는 목적과
사건에 개인 생각을 함께 표출하려는 의도들이 섞이고 섞입니다.
이런 과정을 통해 인터넷은 더 복잡해져 왔습니다.
최적화된 검색 알고리즘과 배경지식의 도움을 받아도 원하는 자료를 찾는 일은 고된일입니다.
글을 쓰며 디지털 자료량 증가 추세를 찾고 정리하는데 한 시간 정도가 소요되었습니다.
생소한 데이터를 바닥부터 찾는 일은 막막하더군요.
쓸모없는 사이트 서른 두가지 이상을 열어보고 원하는 정보 6가지를 찾았습니다.
속이 보이지 않는 열매를 까보며 혼자 답을 찾기는 정말 고됩니다.
#2 손으로 안되면 기계로?
사람힘으로 안되면 기계의 힘을 빌리면 그만입니다.
이러한 배경에서 나온 기술들이 빅데이터와 인공지능입니다.
뻔한 말이니 짧게 하도록 하죠.
빅데이터는 데이터를 구분할 라벨을 붙여 데이터를 대량으로 가공하는 기술입니다.
그 전에는 데이터가 분류되지 않고 용량만 차지했다는 말이 되겠지요.
책이 쌓여만 있던 도서관에 도서 관리 체계로 비유하면 적당하곘군요!
인공지능은 라벨링된 데이터를 바탕으로 원하는 정보를 뱉습니다.
빅데이터가 기반이 되어 등장한 기술입니다.
Chat GPT 같은 생성형 AI만이 아니라 모든 유형의 인공지능은 이 같은 기능을 가집니다.
원하는 정보를 찾아준다.
이를테면, 도서 검색 시스템인 거지요!
2022년과 비교하면 2023년에 ai와 빅데이터 산업 대략 2배 성장한 모습을 보여주며,
2023년 MarketsandMarkets은 이 산업이 연당 36.8% 성장할 거라고 분석하는 보고서를 발행했습니다.

데이터가 늘어나는 상황에서, 그것들을 다룰 도구들이 가치를 인정받는 건 당연한 절차지요.
머신러닝과 빅데이터라는 기술을 사용하여 개인이 직접 데이터를 분석하여 관계를 찾기는 어렵습니다.
정보 과잉 시대에 일반인에게 도움을 주는 관련 기술은 생성형 AI가 전부라 볼 수 있습니다.
개인이 찾기 힘들 정보를 물어보면 뚝딱 알려주는 생성형AI는 정말 매력적입니다.
분명 데이터 과잉 시대에 우리에게 하나의 돌파구가 될 것으로 보입니다.
#3 질문은 가능성의 세계로 향하는 관문이다. (by 유영만 칼럼니스트)
그렇다면 생성형 AI만 있으면 끝도 없이 많은 데이터중 내가 원하는 정보를 찾을 수 있을까요?
아닙니다.
특히 구체적인 수치를 찾아야 하고, 정해진 답이 있는 분야에서는 쓸모 없다고 봐도 무방합니다.
예를 들어 지난 10년간 AI산업 크기의 증가 추세를 알려주는 일은 생성형 AI가 하기는 불가능합니다.
저와 여러분 이제는 생성형 AI도 같습니다.
여기저기서 주워들어 AI가 뜨고 있다는 이야기는 들어봤지만, 구체적인 수치는 모릅니다.
전에 어렴풋이 들은 말로 맞는 거 같은 말을 할 뿐입니다.
그렇기 때문에 결국 우리는 속에 뭐가 들어있는지 모를 열매를 까보아야 합니다.
쓰레기일지도 모르는 사이트에 접속하여 글을 읽어보고, 원하는 정보를 찾아내야합니다.
그러기 위해서는, 내가 어떠한걸 알고 싶은지 정확히 아는 게 중요합니다.
올바른 정답을 찾으려면 올바른 질문을 해야 합니다.
나무를 베는 데 6시간을 준다면, 4시간은 도끼날을 가는 데 쓸 것이다.
(Give me six hours to chop down a tree and I will spend the first four sharpening the axe.)
_ 에이브러햄 링컨(Abraham Lincoln)
#4 발길이 닿는 곳에는 길이 나기 마련입니다.
작은 서비스 소개를 겸해, 올바른 질문을 던져야 한다는 말보다 하나 더 나아가볼까 합니다.
그 분야에 대해 아는 게 없다면 어떤 질문을 해야 하는 지 모를 상황을 맞닥뜨립니다.
숲에서 길을 잃었을때, 처음 보는 개념을 인터넷에서 찾아야 할 때 드는 생각이 있었습니다.
남들이 간 길을 표시해주면 방향을 잡을 수 있을 텐데.
검색 결과에 이전 사용자가 표시를 남겨주면 좋을 텐데.
우거진 숲에 사람이 지나간 곳에는 자국이 남기 마련입니다.
사람들이 많이 지나간 자리는 이후에도 사람들이 다닐 길이 되어주고요.
검색 엔진에도 이전 사용자들이 어디로 가야 할지 표시를 해주면 얼마나 좋을까요?
…!
이러한 생각을 가지고 배포하기 시작한 서비스가 있습니다. [링크]
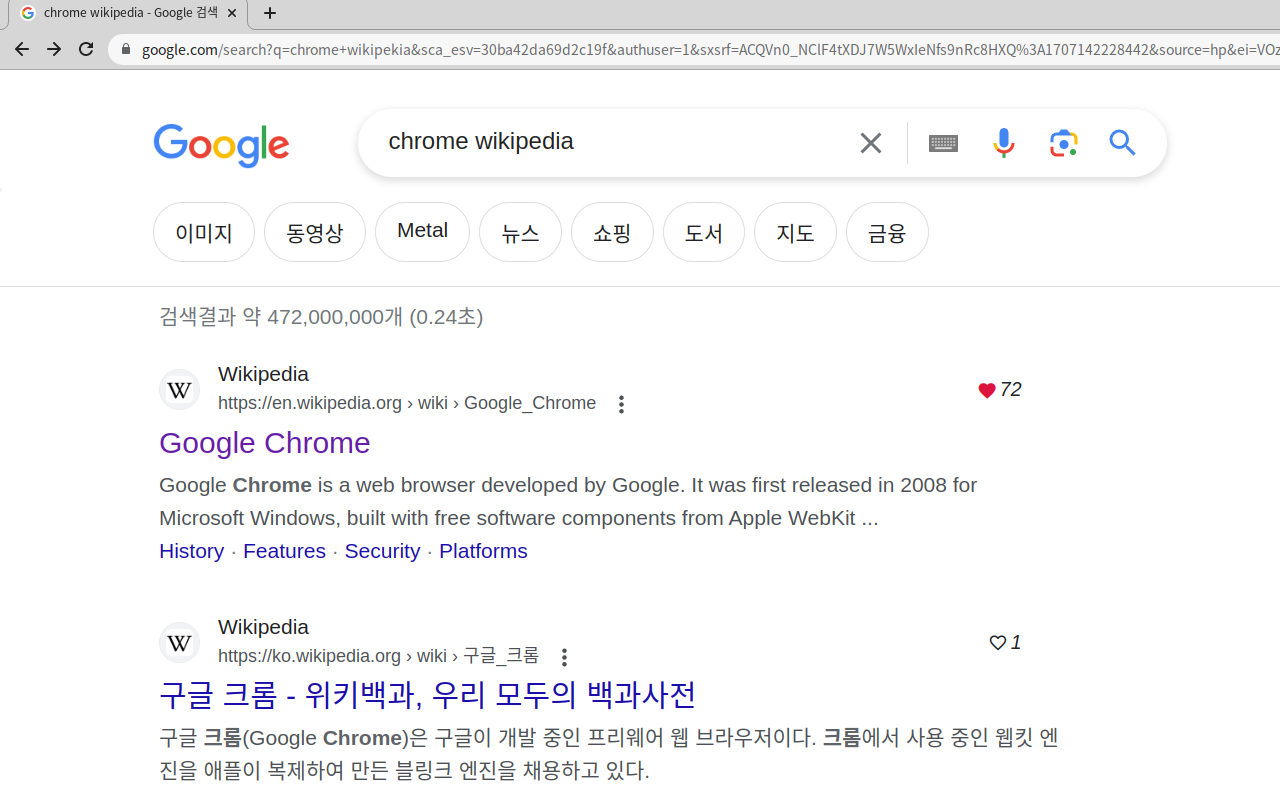
검색 엔진의 검색결과에 ”좋아요“ 기능을 추가하자는 목적으로 searchPlusLike라는 프로젝트는 크롬 확장프로그램으로 릴리즈 되었습니다.
간단히 검색결과 오른편에 이전 사용자들의 좋아요를 보여주는 서비스입니다.
물론 직접 좋아요를 눌러 페이지를 평가할 수도 있지요.
분명 사람들이 함께 찾아준다면 수많은 정보중 원하는 결과를 찾는데 도움이 될 겁니다.
👉 [링크] 그럼, 세상 모든 페이지에 함께 좋아요를 눌러볼까요?
+참고사항
1. 크롬 확장 프로그램이란 크롬 브라우저가 PC환경에서 제공하는 추가 기능들입니다. 대표적으로는 광고 차단, 자동번역 서비스 등이 있습니다.
2. 크롬(Chrome), 엣지(Edge) 브라우저에서 사용 가능합니다.
그럼 여기까지 이상이었습니다!
✔️ 정보 과잉시대에 대한 대책을 찾아봅니다.
✔️ 정독까지 1분 38초
✔️ 정보를 바탕으로 전개하는 주장글
#0 끝도 없이 늘어나는 데이터들. 지금도 앞으로도.
IDC (International Data Corporation) 는 매년 디지털 데이터양에 관한 보고서를 발표합니다.
2005년에 0.13 제타바이트
…2012년에 2.8 제타바이드
…2020년에는 90 제타바이트
2025년에 생산/유통 될 디지털 데이터양은 175 제타바이트로 예측됩니다.😵
제타바이트가 실감이 안 나는 사람을 위해 가벼운 예시를 하나 들어볼까요?
1제타바이트는 2^70바이트 입니다.
이러면 조금 더 체감될까요.
8제타바이트를 바이트로 환산하면, 전 세계의 모래알 수와 비슷합니다!
불과 10년 만에 700배에 가까운 데이터가 생겨났습니다.
2012년에 IDC는 2020년 디지털 정보량이 40제타바이트에 보달할거라 예측했습니다.
허나 2020년 데이터양은 90제타바이트 이상으로 예측을 두 배 이상 웃돌고 있습니다.
과학이 발전함에 따라, 우리는 개인이 받아드리기에는 너무 많은 사실들을 알아냈습니다.
정보가 홍수처럼 범람하는 시대, 정보의 바다라는 말이 지겹도록 들리는 이유겠지요.
#1 알맹이 없는 열매를 까보는 노력들.
2012년 0.5%에 데이터만이 분석되었습니다. 보호받는 데이터는 19%에서 그쳤고요.
앞서 말했듯이, 정보는 기하급수적으로 정보는 늘어납니다.
그에 반해 유의미한 데이터는 정보 팽창속도에 비하면 충분히 확보되지 않는다고 봐도 무방해 보이고요.
이는 무의미한 데이터가 생산되기 때문이라고도 볼 수 있습니다.
하나의 사실로도 많은 디지털 컨텐츠가 생산됩니다.
블로그로, 커뮤니티로, 유튜브 채널로, 뉴스로, 그리고 스타트업 같은 새로운 서비스로.
인터넷이라는 공간은 점점 더 넓어지고 빼곡히 채워집니다.
빽뺵히.
세상은 점점 넓어지는데
같은 사실로 쓸모없는 컨텐츠들이 생산되고
알아야할 사실은 늘어만 가니
우후죽순 넓어지는 정보 사이에서 길을 잃는게 일상입니다.
순전히 정보를 이해하기 쉽게 전달하려는 생각과
금전전 이익을 취하려는 목적과
사건에 개인 생각을 함께 표출하려는 의도들이 섞이고 섞입니다.
이런 과정을 통해 인터넷은 더 복잡해져 왔습니다.
최적화된 검색 알고리즘과 배경지식의 도움을 받아도 원하는 자료를 찾는 일은 고된일입니다.
글을 쓰며 디지털 자료량 증가 추세를 찾고 정리하는데 한 시간 정도가 소요되었습니다.
생소한 데이터를 바닥부터 찾는 일은 막막하더군요.
쓸모없는 사이트 서른 두가지 이상을 열어보고 원하는 정보 6가지를 찾았습니다.
속이 보이지 않는 열매를 까보며 혼자 답을 찾기는 정말 고됩니다.
#2 손으로 안되면 기계로?
사람힘으로 안되면 기계의 힘을 빌리면 그만입니다.
이러한 배경에서 나온 기술들이 빅데이터와 인공지능입니다.
뻔한 말이니 짧게 하도록 하죠.
빅데이터는 데이터를 구분할 라벨을 붙여 데이터를 대량으로 가공하는 기술입니다.
그 전에는 데이터가 분류되지 않고 용량만 차지했다는 말이 되겠지요.
책이 쌓여만 있던 도서관에 도서 관리 체계로 비유하면 적당하곘군요!
인공지능은 라벨링된 데이터를 바탕으로 원하는 정보를 뱉습니다.
빅데이터가 기반이 되어 등장한 기술입니다.
Chat GPT 같은 생성형 AI만이 아니라 모든 유형의 인공지능은 이 같은 기능을 가집니다.
원하는 정보를 찾아준다.
이를테면, 도서 검색 시스템인 거지요!
2022년과 비교하면 2023년에 ai와 빅데이터 산업 대략 2배 성장한 모습을 보여주며,
2023년 MarketsandMarkets은 이 산업이 연당 36.8% 성장할 거라고 분석하는 보고서를 발행했습니다.
데이터가 늘어나는 상황에서, 그것들을 다룰 도구들이 가치를 인정받는 건 당연한 절차지요.
머신러닝과 빅데이터라는 기술을 사용하여 개인이 직접 데이터를 분석하여 관계를 찾기는 어렵습니다.
정보 과잉 시대에 일반인에게 도움을 주는 관련 기술은 생성형 AI가 전부라 볼 수 있습니다.
개인이 찾기 힘들 정보를 물어보면 뚝딱 알려주는 생성형AI는 정말 매력적입니다.
분명 데이터 과잉 시대에 우리에게 하나의 돌파구가 될 것으로 보입니다.
#3 질문은 가능성의 세계로 향하는 관문이다. (by 유영만 칼럼니스트)
그렇다면 생성형 AI만 있으면 끝도 없이 많은 데이터중 내가 원하는 정보를 찾을 수 있을까요?
아닙니다.
특히 구체적인 수치를 찾아야 하고, 정해진 답이 있는 분야에서는 쓸모 없다고 봐도 무방합니다.
예를 들어 지난 10년간 AI산업 크기의 증가 추세를 알려주는 일은 생성형 AI가 하기는 불가능합니다.
저와 여러분 이제는 생성형 AI도 같습니다.
여기저기서 주워들어 AI가 뜨고 있다는 이야기는 들어봤지만, 구체적인 수치는 모릅니다.
전에 어렴풋이 들은 말로 맞는 거 같은 말을 할 뿐입니다.
그렇기 때문에 결국 우리는 속에 뭐가 들어있는지 모를 열매를 까보아야 합니다.
쓰레기일지도 모르는 사이트에 접속하여 글을 읽어보고, 원하는 정보를 찾아내야합니다.
그러기 위해서는, 내가 어떠한걸 알고 싶은지 정확히 아는 게 중요합니다.
올바른 정답을 찾으려면 올바른 질문을 해야 합니다.
나무를 베는 데 6시간을 준다면, 4시간은 도끼날을 가는 데 쓸 것이다.
(Give me six hours to chop down a tree and I will spend the first four sharpening the axe.)
_ 에이브러햄 링컨(Abraham Lincoln)
#4 발길이 닿는 곳에는 길이 나기 마련입니다.
작은 서비스 소개를 겸해, 올바른 질문을 던져야 한다는 말보다 하나 더 나아가볼까 합니다.
그 분야에 대해 아는 게 없다면 어떤 질문을 해야 하는 지 모를 상황을 맞닥뜨립니다.
숲에서 길을 잃었을때, 처음 보는 개념을 인터넷에서 찾아야 할 때 드는 생각이 있었습니다.
남들이 간 길을 표시해주면 방향을 잡을 수 있을 텐데.
검색 결과에 이전 사용자가 표시를 남겨주면 좋을 텐데.
우거진 숲에 사람이 지나간 곳에는 자국이 남기 마련입니다.
사람들이 많이 지나간 자리는 이후에도 사람들이 다닐 길이 되어주고요.
검색 엔진에도 이전 사용자들이 어디로 가야 할지 표시를 해주면 얼마나 좋을까요?
…!
이러한 생각을 가지고 배포하기 시작한 서비스가 있습니다. [링크]
검색 엔진의 검색결과에 ”좋아요“ 기능을 추가하자는 목적으로 searchPlusLike라는 프로젝트는 크롬 확장프로그램으로 릴리즈 되었습니다.
간단히 검색결과 오른편에 이전 사용자들의 좋아요를 보여주는 서비스입니다.
물론 직접 좋아요를 눌러 페이지를 평가할 수도 있지요.
분명 사람들이 함께 찾아준다면 수많은 정보중 원하는 결과를 찾는데 도움이 될 겁니다.
👉 [링크] 그럼, 세상 모든 페이지에 함께 좋아요를 눌러볼까요?
+참고사항
1. 크롬 확장 프로그램이란 크롬 브라우저가 PC환경에서 제공하는 추가 기능들입니다. 대표적으로는 광고 차단, 자동번역 서비스 등이 있습니다.
2. 크롬(Chrome), 엣지(Edge) 브라우저에서 사용 가능합니다.
그럼 여기까지 이상이었습니다!